A Software Engineer's Introduction to ML Practice
A summary of the most relevant literature that helped me to get started

Several months ago, I revisited the realm of AI, a field I had briefly explored during my tenure at Uber, where I contributed to ML-related infrastructure. Since then, the landscape has evolved significantly, prompting me to immerse myself in a myriad of resources to catch up.
This journey led to the compilation of a resource list, initially intended for my engineering team. Realizing its broader value, I transformed it into a blog post, aiming to guide those venturing into AI, particularly software engineers with great experience in coding and distributed systems, looking to transition into ML in the shortest amount of time.
My learning path is structured, starting with foundational concepts and advancing toward practical application, mirroring my personal growth in the field.
Understanding ML fundamentals
I advocate for a bottom-up learning approach. Just like mastering programming requires an understanding of algorithms and data structures, excelling in a new technology like AI necessitates a solid grasp of the basics. This approach, though seemingly more arduous, ensures a broad comprehension, crucial for future advancements.
So, before jumping straight into the world of AI and LLMs, I found it particularly helpful to brush up on some ML fundamentals.
(1) The Deep Learning Textbook by Ian Goodfellow, Yoshua Bengio, and Aaron Courville https://www.deeplearningbook.org

This is a somewhat classic textbook on the most fundamental math behind Machine Learning. I’m not gonna lie, it was a tough and humbling read at times and made me go back to some math basics that I studied at university to grasp everything in this book. I might come back to it from time to time to brush up and practice on some specific areas that I still don’t feel 100% comfortable with.
(2) Deep Learning with Python https://www.amazon.com/Deep-Learning-Python-Francois-Chollet/dp/1617294438/
A great book that I read a couple of times, with lots of practical examples and theory. Very useful to have on the desk and get back to it from time to time.
The only problem with these kinds of books is that they quickly go out of sync with the latest industry updates. Still, I do not regret having it handy as it covers some basics too.
(3) Practical Deep Learning for Coders by Fast.ai https://course.fast.ai/Lessons/lesson1.html
A truly fantastic course for programmers to get started with ML and deep learning without much prior ML experience. It’s a relatively fast way to become an ML practitioner for those who have strong enough fundamentals in CS, great coding, and distributed systems experience. Python experience is helpful, but not a requirement.
The course is not intimidating, it starts by getting you to a trained model in the first lesson so that you don’t feel like it’s daunting at lesson 10 and you haven’t even started coding yet.
And, Jeremy Howard is a fantastic tutor and narrator, I highly recommend this course for anyone getting started.
(4) Introduction to Deep Learning by Sebastian Raschka https://sebastianraschka.com/blog/2021/dl-course.html
A great resource that offers a series of courses covering a range of topics in deep learning. The courses are divided into five parts, focusing on foundational aspects, math, NNs, deep learning applications in language modeling, and deep generative models.
Each section includes detailed video lectures and practical code examples in PyTorch as well.
I found it equally great for beginners and practitioners too, who are familiar with general concepts already.
Understanding Large Language Models
In this part, I am covering the theory behind LLMs and generative AI, with a focus mostly on transformer-based architectures.
(1) Text Embeddings
I can’t emphasize enough how important the text embeddings are in further understanding LLMs. This is one of the core components that requires some studying before diving into LLMs themselves.
So, here, I decided to include several resources about text embeddings that I found particularly great:
Text Embeddings Visually Explained by Cohere https://txt.cohere.com/text-embeddings/
A very insightful guide to understanding text embeddings. It explains how large language models convert text into numerical representations, capturing their semantic meanings. It further dives into practical applications of text embeddings, such as in semantic search, clustering, and classification.An intuitive introduction to text embeddings by Kevin Henner https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
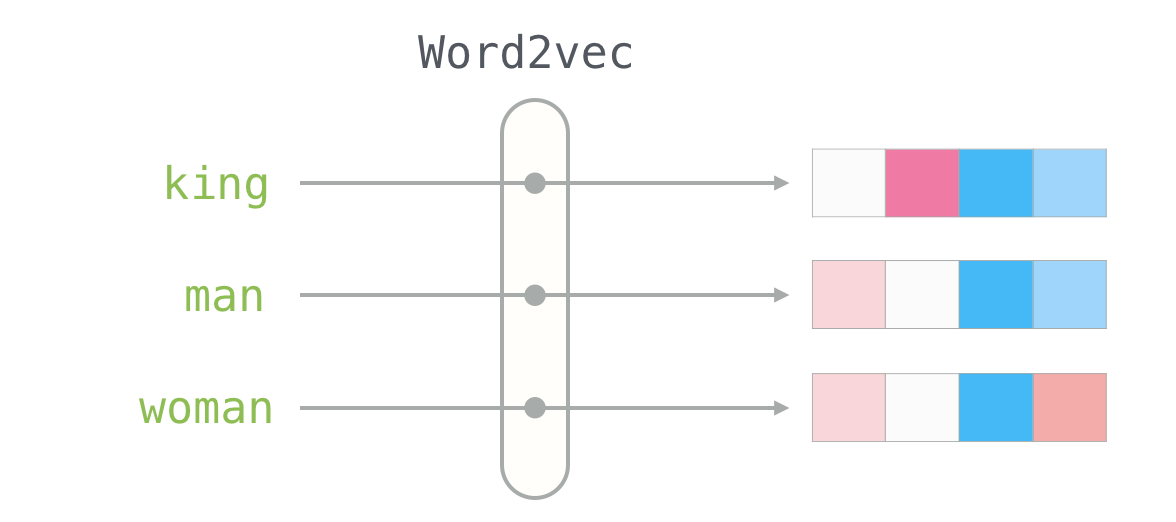
Another great article covering text embedding basics. It also covers practical applications like semantic search and content moderation, but in addition delves into various aspects of embedding spaces, distance metrics, and the role of embeddings in machine learning algorithms. It also touches on advanced topics like the transformer architecture in large language models (LLMs) and the application of these concepts in multi-modal models and robotics.The Illustrated Word2vec by Jay Alammar https://jalammar.github.io/illustrated-word2vec/
This is an in-depth visual explanation of the Word2vec algorithm, a popular method for creating word embeddings in natural language processing. While there are various algorithms and text embedding models out there Word2Vec is the most basic and useful to understand. It’s also pretty straightforward to implement and there is a bunch of implementations available on GitHub to study.This article is particularly valuable for those seeking a clear, visual understanding of how Word2vec works.
(2) Attention is All You Need by Google https://arxiv.org/pdf/1706.03762.pdf
This is the most fundamental paper that introduces transformer architecture and requires no introduction.
There isn’t much to add here other than it’s a must-read.
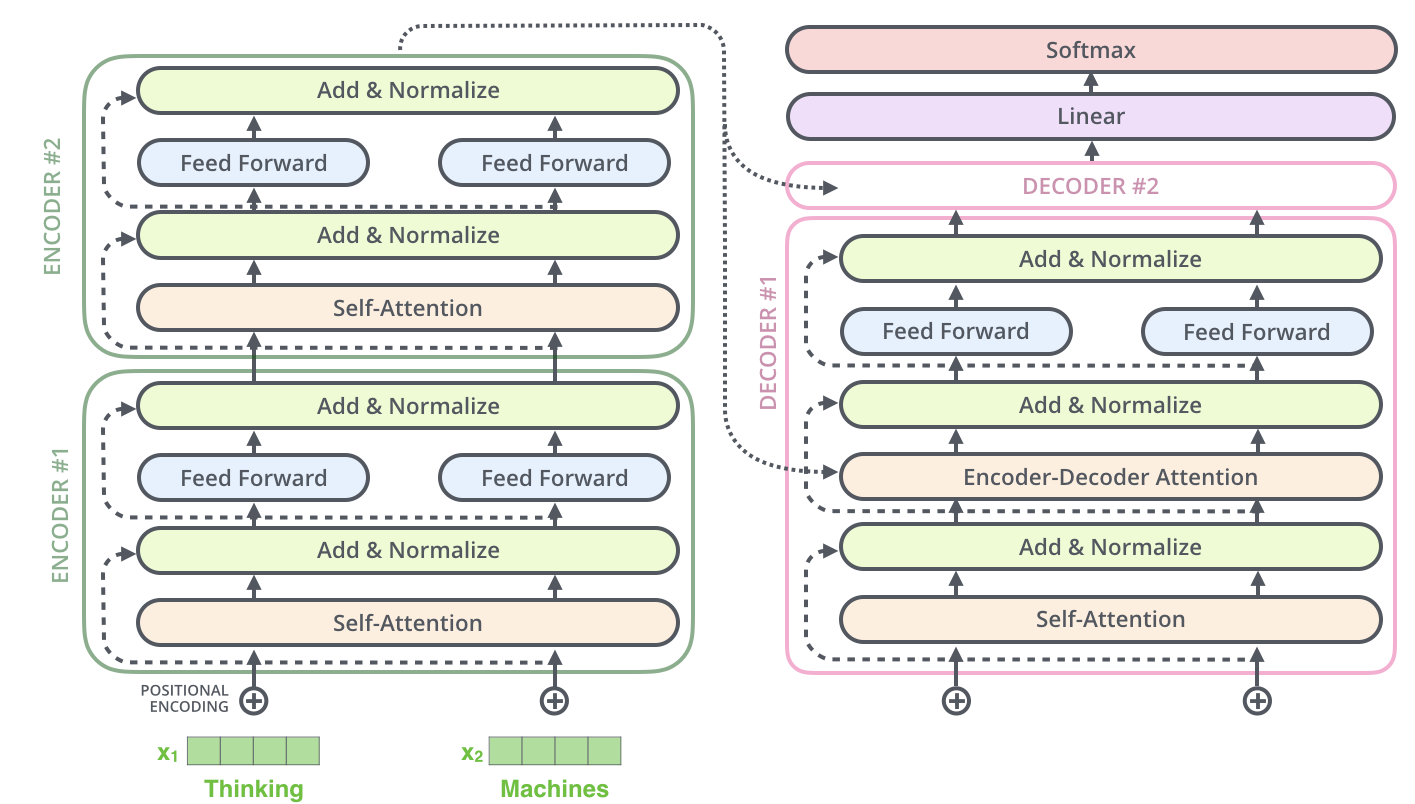
(3) The Illustrated Transformer by Jay Alammar https://jalammar.github.io/illustrated-transformer/
An excellent visual guide into the Transformer architecture that breaks down the complex architecture, including its encoding and decoding components, and explains key concepts like self-attention, positional encoding, and multi-headed attention in an accessible manner. The article also dives into how these components interact within the model, making it easy to connect the dots.
(4) LLM Foundations by Sergey Karayev https://fullstackdeeplearning.com/llm-bootcamp/spring-2023/llm-foundations/
Fantastic talk! A great introduction to ML fundamentals first, the types of learning approaches, which then goes into an overview of NN layers, perceptrons, and neurons for general understanding. In the second half, it provides an amazing overview of the transformer architecture step by step and an overview of training methods, model architectures, etc.
(5) Let's build GPT: from scratch, in code, spelled out by Andrej Karpathy
Fantastic video where Andrej goes through building GPT, inspired by the “Attention is All You Need” paper and OpenAI's GPT-2/GPT-3 models step-by-step.
You don’t want to miss this one. In the end, a great exercise would be to implement it yourself.
(6) LLaMA: Open and Efficient Foundation Language Models by Meta AI https://arxiv.org/pdf/2302.13971.pdf
A paper on the most popular open-source LLM to date from Meta AI. This is by far the most mainstream and popular open-source model that is worth paying attention to. A ton of great materials are all over the internet, full of practical examples of fine-tuning, inferencing, optimization, etc. This is also one of the best-performing open-source LLMS out there at this moment.
(7) Understanding Large Language Models by Sebastian Raschka https://magazine.sebastianraschka.com/p/understanding-large-language-models
A very comprehensive list of fundamental papers, articles, and courses about LLMs. This was by far my favorite source of materials to study that helped me to get going, and very much inspired this post.
(8) The Annotated Transformer by Austin Huang, Suraj Subramanian, Jonathan Sum, Khalid Almubarak, and Stella Biderman, Sasha Rush. https://nlp.seas.harvard.edu/annotated-transformer/
For all the coders out there this is by far one of the best annotated line-by-line implementations of the Attention is All You Need paper.
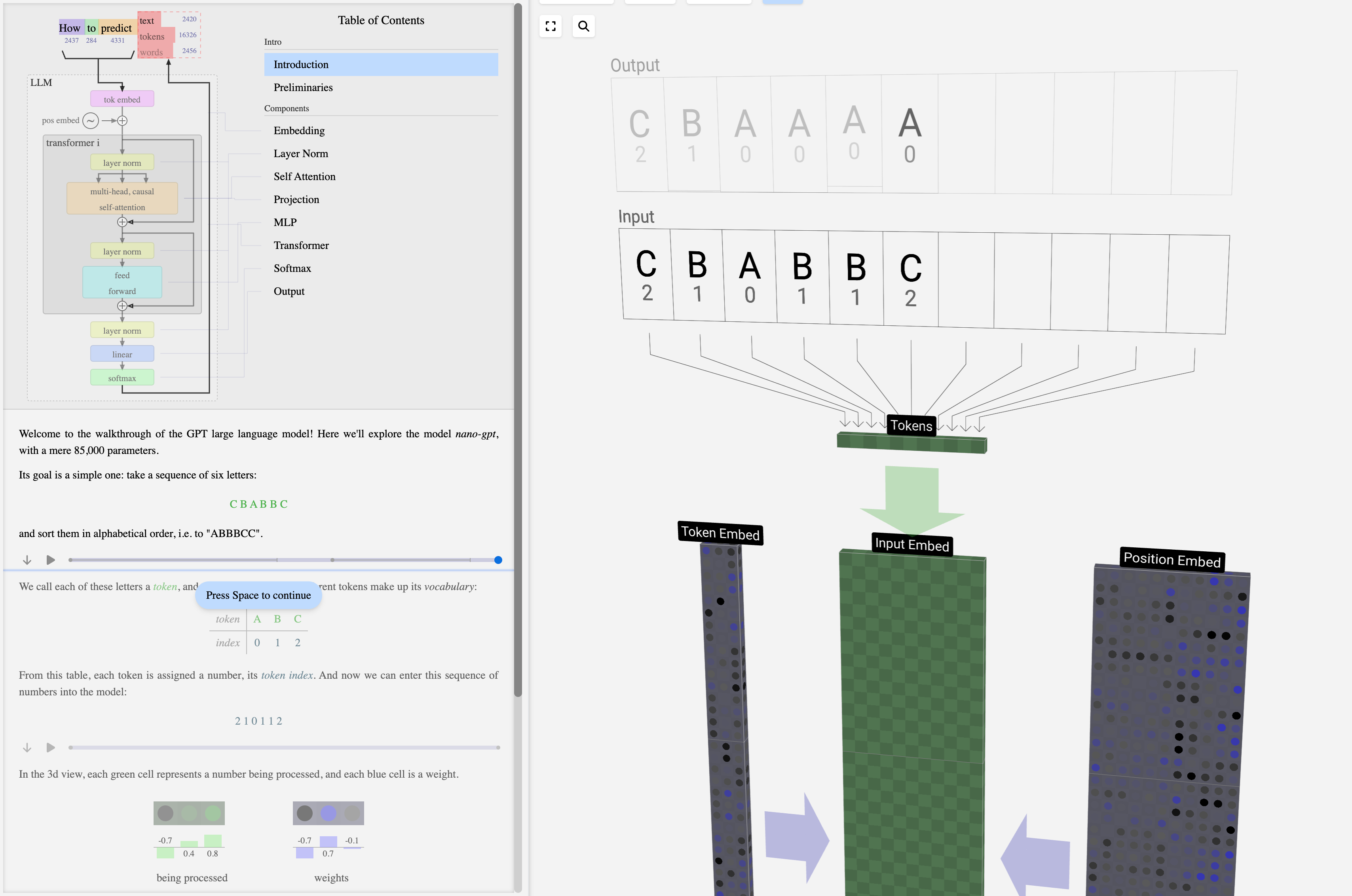
(9) LLM Visualization https://bbycroft.net/llm
Great interactive visualization of all the layers of an LLM for anyone looking to get a deep view of the architecture and explore each layer of a model. Pretty great work.
Practitioner’s Corner
Now, that we have all the basics covered, this section offers a comprehensive list of all the things to start doing some real work.
(1) Efficiently Scaling Transformer Inference by Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, Jeff Dean https://arxiv.org/pdf/2211.05102.pdf
The paper addresses the challenge of generative inference for large Transformer models with low latency targets and long sequence lengths. It discusses engineering trade-offs for efficient inference, and developing a model for inference efficiency, particularly for models with over 500B parameters.
While this may not be the most practical paper for most engineers, I found it is still helpful to read to get a broad understanding and ideas about various inference optimization techniques.
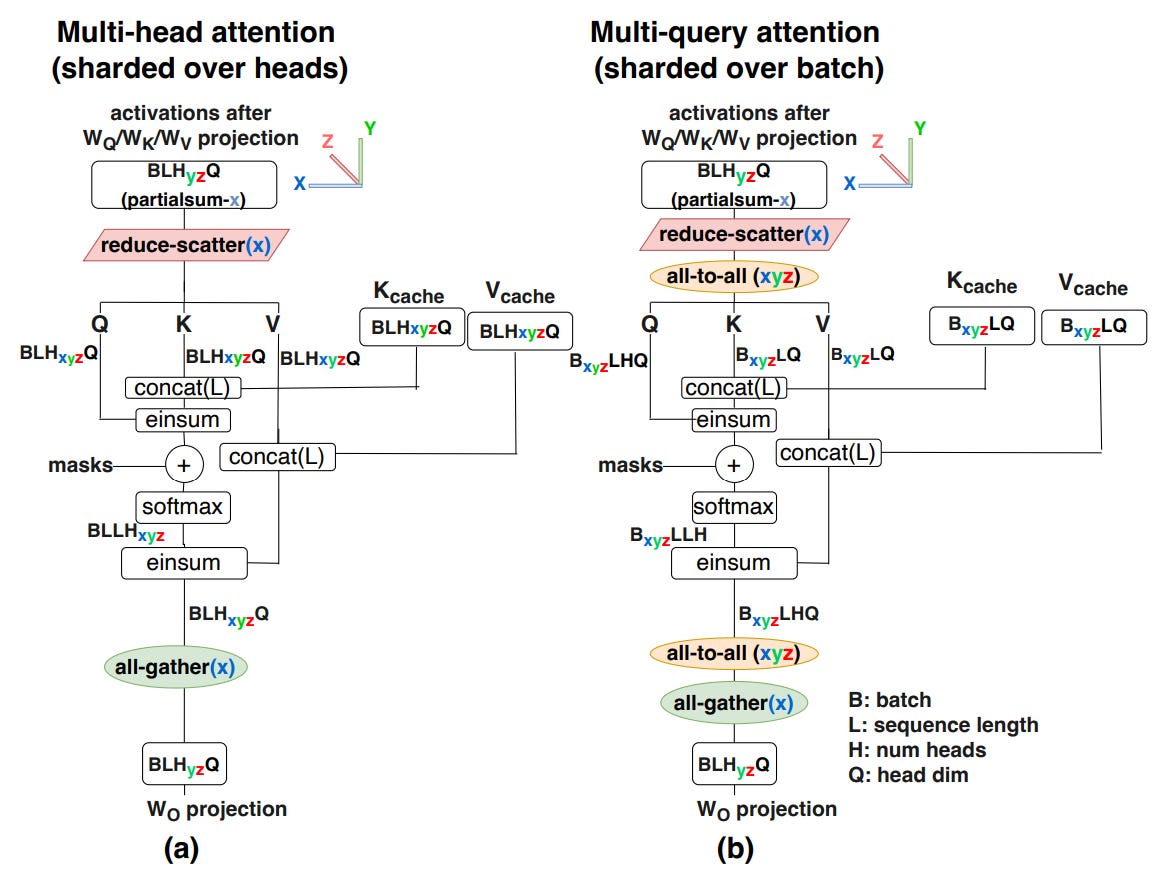
(2) In-context Learning and Induction Heads by Anthropic https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html#definition-of-induction-heads
An in-depth paper discussing in-context learning and various aspects of trying to understand/reverse engineer the model’s learning and activation processes under various conditions. The authors provide evidence to support the hypothesis that induction heads may be responsible for the majority of in-context learning in transformer models.
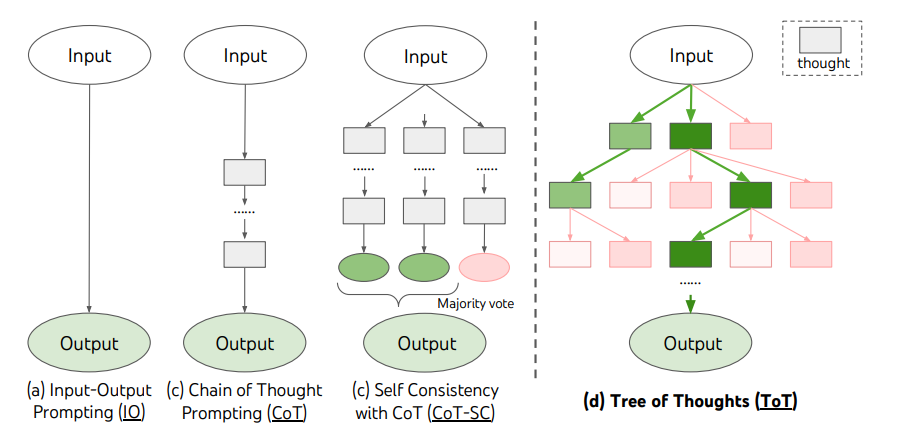
(3) Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan https://arxiv.org/pdf/2305.10601.pdf
This fantastic paper describes a ToT approach, which enables a much better LLM’s problem-solving capabilities. The main characteristic of this approach is that the algorithm can find the most optimal solution over a tree of possible solutions where LLM is used to produce thoughts which are then represented as nodes of the tree.
The nodes of the tree define heuristics the sum of which leads to the most optimal solution. As such, any graph exploration algorithm is sufficient to find the most optimal chain of thought for the solution. Notably, the paper mentions BFS or DFS as the most simple algorithms (A* could be used too).
(4) Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes by Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, Tomas Pfister https://arxiv.org/pdf/2305.02301.pdf
Great paper proposing an approach to fine-tuning smaller, and inherently much cheaper models, to outperform much larger LLMs on specific tasks. This is especially relevant for scaling models in production that are supposed to solve specific business tasks with a focus on high-quality and proprietary data. The paper shows that this approach in most cases outperforms LLMs by a large margin while being substantially cheaper and requiring almost x2000 less training data.
And while this is not the most novel idea anymore, the paper does a great job covering important principles and methods behind it.

(6) A Comprehensive Guide for Building RAG-based LLM Applications by Goku Mohandas and Philipp Moritz https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
Great article and a notebook with a detailed step-by-step guide about building RAG-based LLM applications. Very good for understanding the development process end to end, the approach of in-context prompting, the application of vector databases for indexing context data, and evaluation techniques for model tuning/quality assessment.
(7) Mastering LLM Techniques: Inference Optimization by Shashank Verma and Neal Vaidya https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
Another article about inference optimization, this time from Nvidia. The article explores various batching techniques, model parallelization (including pipeline, tensor, and sequence parallelism), and attention mechanism optimizations like multi-head and grouped-query attention.
Additionally, it covers efficient management of key-value caches and model optimization techniques like quantization, sparsity, and distillation, crucial for enhancing LLM performance in production.
It is particularly useful for those working on the infrastructure side or looking for ways to deploy their custom fine-tuned models in production more cost-efficiently.
The above list is what helped me to get started on my ML practitioner path. Overall, it took about a month and a half to go through all of it, write some code, experiment, and fine-tune a couple of models myself, one of which we put into production.
My journey in AI is ongoing. I keep learning every day and every week. The pace of innovation in the AI space is truly remarkable and at times it might be challenging to keep up with everything that’s going on, there is also a lot of noise to filter through.
Generally, I study two or three papers a week and attempt to test/implement at least one of them. I will do my best to summarize the best of the best, including my learnings in a monthly digest which I will post in this blog.
If you liked this article, please consider subscribing to my blog, and I would appreciate it if you could share it with your colleagues and friends.